
À propos du dépôt des données
Résumé de section
-
-
Qu'entend-on par déposer ses données ?
Il existe de nombreux services pour stocker ses fichiers sur le cloud. Google Drive et One Drive font partie des plus connus. Si ces solutions peuvent être adaptées à des fins personnelles, elles ne devraient pas l'être en ce qui concerne des données issues d'un travail de recherche. En effet, les données issues d’un travail de recherche ont un statut particulier. Elles ont un intérêt pour la communauté scientifique et forment un bien commun. Elles nécessitent donc une attention particulière en termes de conditions d'accès, d'hébergement, d'usage, de sécurité, d'infrastructure technique...
De ce fait, les entrepôts de données (data repositories) sont des plateformes qui fournissent des services profilés pour les données scientifiques. Mais avant d'aller plus loin, attardons-nous un instant sur la différence entre stockage et diffusion (dépôt de données).

Le dépôt des données dans un entrepôt rentre dans une logique de diffusion et de partage.
La phase de stockage
Durant un projet de recherche, les membres de l'équipe produisent ou collectent des données afin de valider ou produire des résultats. Ces données peuvent être très variées : données expérimentales (obtenues à partir d’équipements de laboratoire), données d’observation (neuroimageries, photographies astronomiques, données d’enquête...), données computationnelles (modèles météorologiques, modèles de simulation sismique, modèles économiques), etc.
Toutes ces données en cours d'élaboration ont besoin d'être stockées quelque part et être accessibles, le plus souvent aux seuls membres de l'équipe. Les supports de stockage utilisés sont généralement les disques durs des ordinateurs, les serveurs ou les services cloud du laboratoire ou de l’institution.
Cette "phase de stockage" n’est pas prise en charge par les entrepôts de données.
La phase de diffusion
En fin de projet, l'article scientifique doit être soumis à un comité de lecture pour évaluation et validation. Afin d'améliorer les conditions d'évaluation, les données sous-jacentes à l'article sont aussi de plus en plus demandées. Ainsi, le texte et les données sous-jacentes doivent être accessibles au comité de lecture (on notera que les figures, tableaux et autres visuels contenus dans le texte sont à considérer comme des données intégrées).
C'est là qu'entre en jeu le dépôt des données dans un entrepôt. Les entrepôts facilitent l'accès et l'intelligibilité des données, aspects nécessaires au travail des évaluateurs, mais aussi à tout lecteur de l’article en question. Outre le travail du comité de lecture, les entrepôts offrent aux communautés scientifiques un accès optimum aux données, une transparence de la recherche, une reconnaissance de la paternité des travaux, une possible réutilisation et une possible reproductibilité.
La phase d'archivage
Lorsque le projet est terminé, une phase d'archivage ou de préservation peut être aussi envisagée. Elle consiste à sélectionner les données que l'on souhaite préserver car elles ont une utilité sur le long terme. On a alors recours à des centres d'archivages qui traitent les données pour qu'elles soient lisibles dans le temps.
Les entrepôts de données correspondent donc à une logique de diffusion et de partage. Il y a d'autres façons de diffuser des données (fichier annexé au texte, carnet de recherche en ligne...), mais ces aspects ne seront pas approfondis ici car ils sont moins conformes aux principes FAIR.
-
Qu'est-ce qu'un entrepôt de données ?
Pour le dire simplement, les entrepôts de données sont des plateformes web sur lesquelles les chercheurs peuvent déposer et rechercher des données scientifiques. Ils proposent des services spécifiques à l'activité de recherche (description des jeux de données, choix des conditions d'accès, attribution de licence...) et offrent une garantie de sécurité. La plupart présente un système de recherche détaillé avec de nombreux filtres.
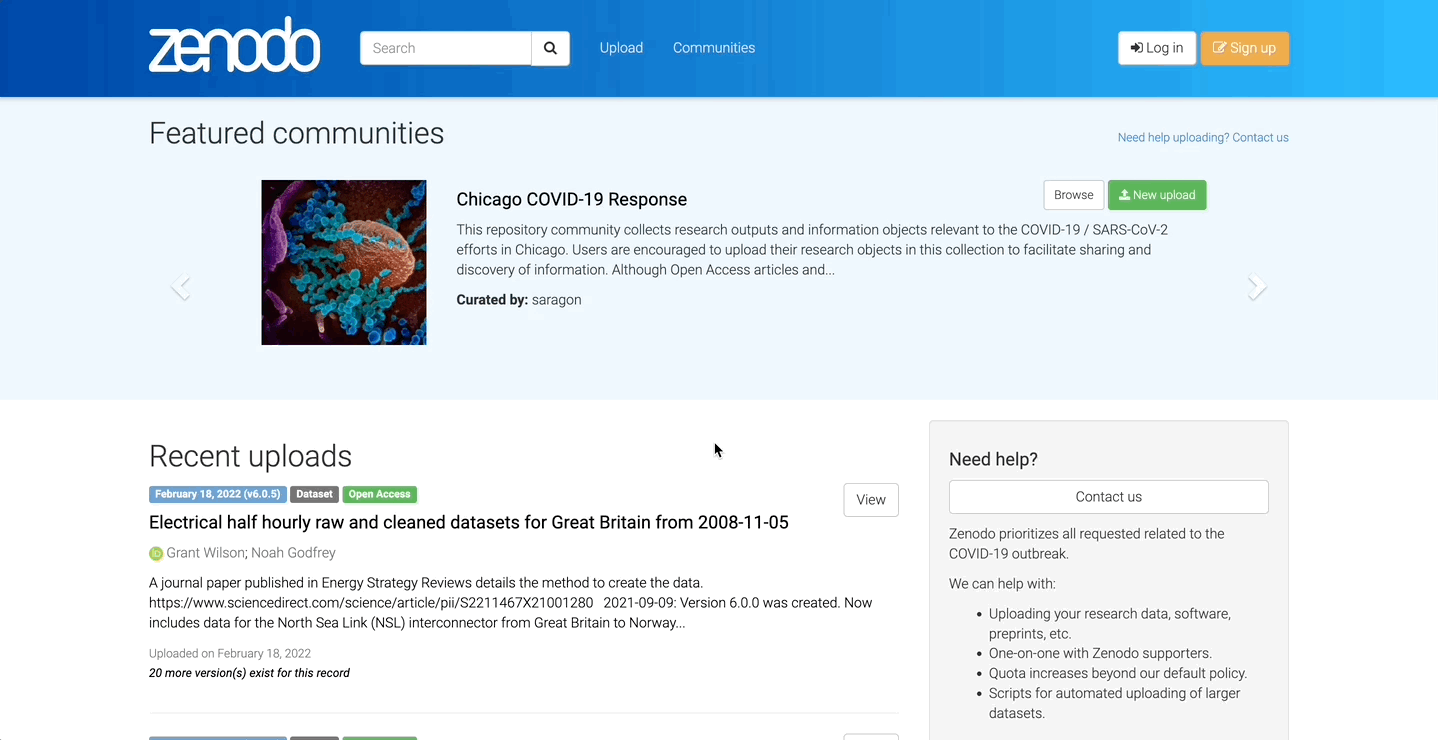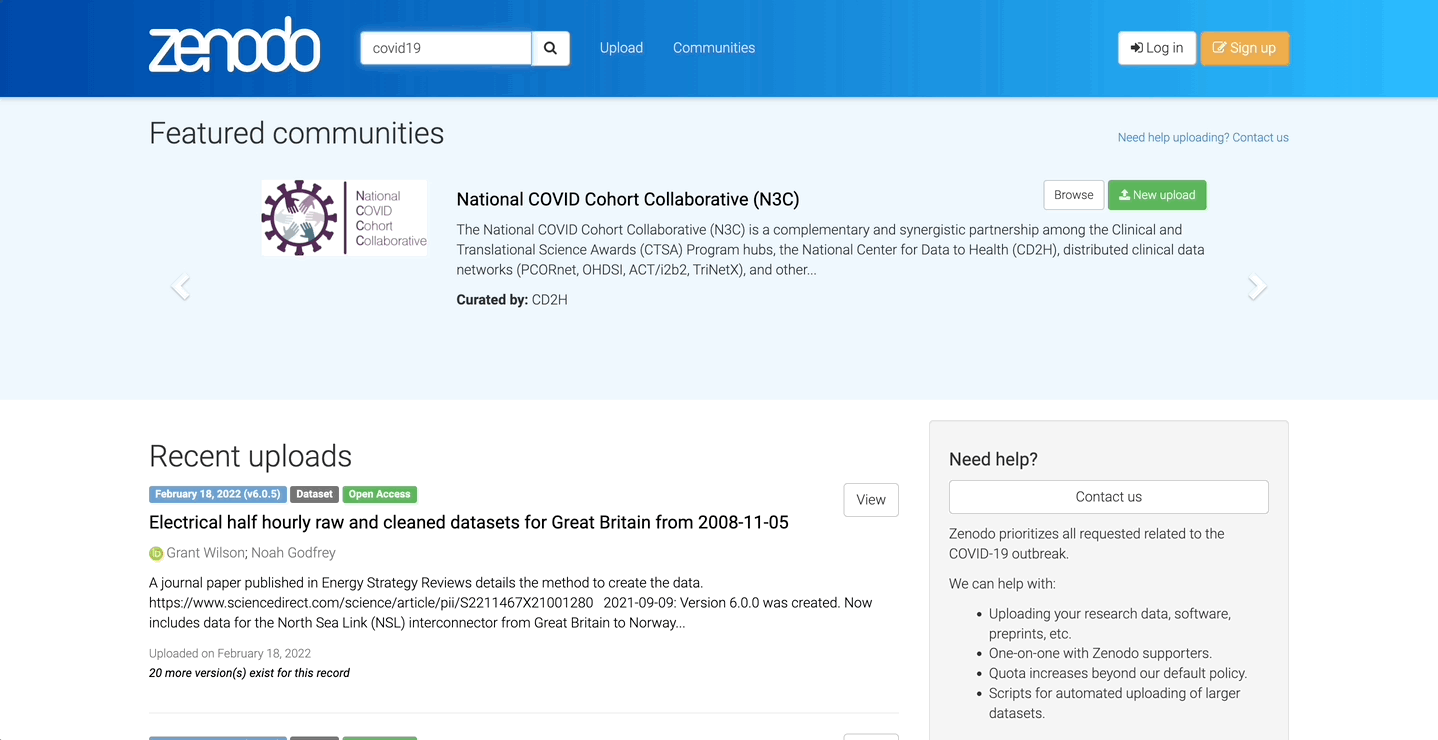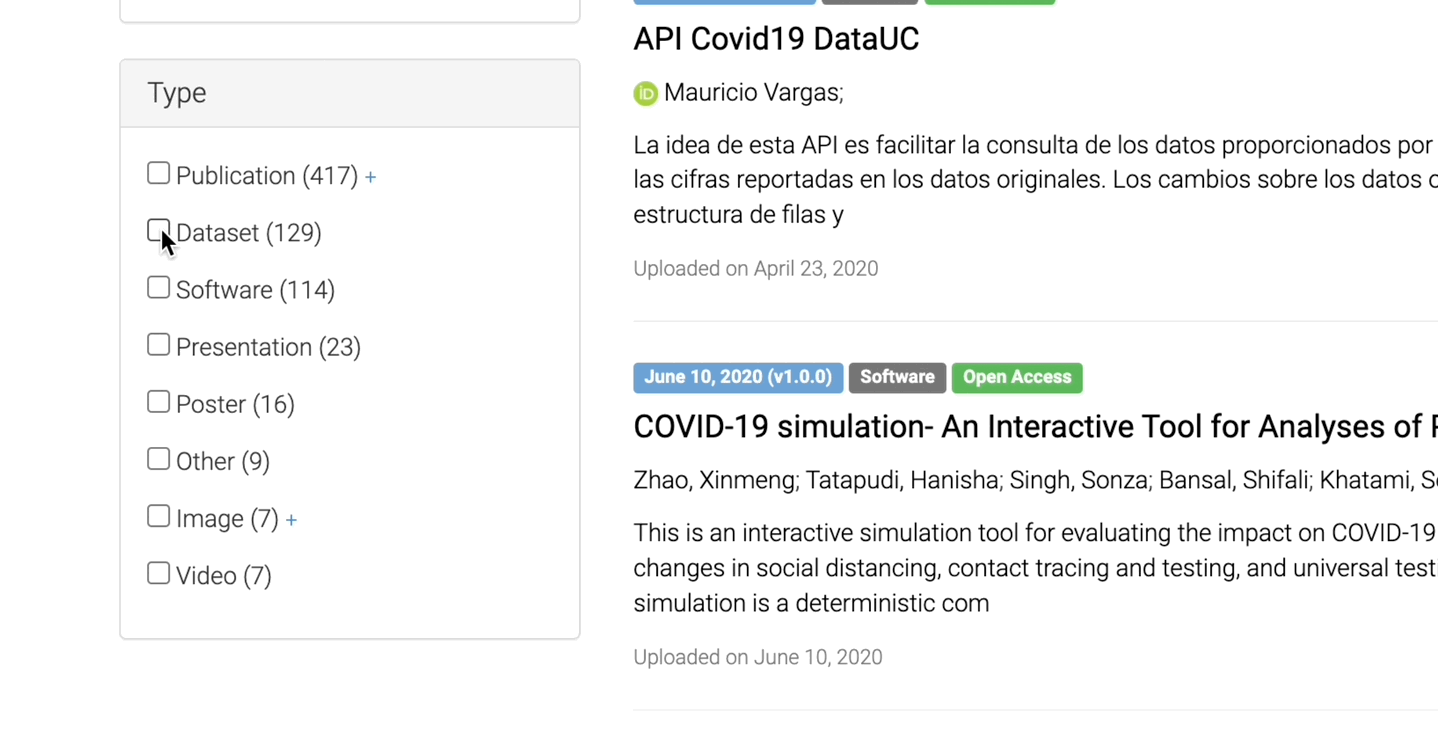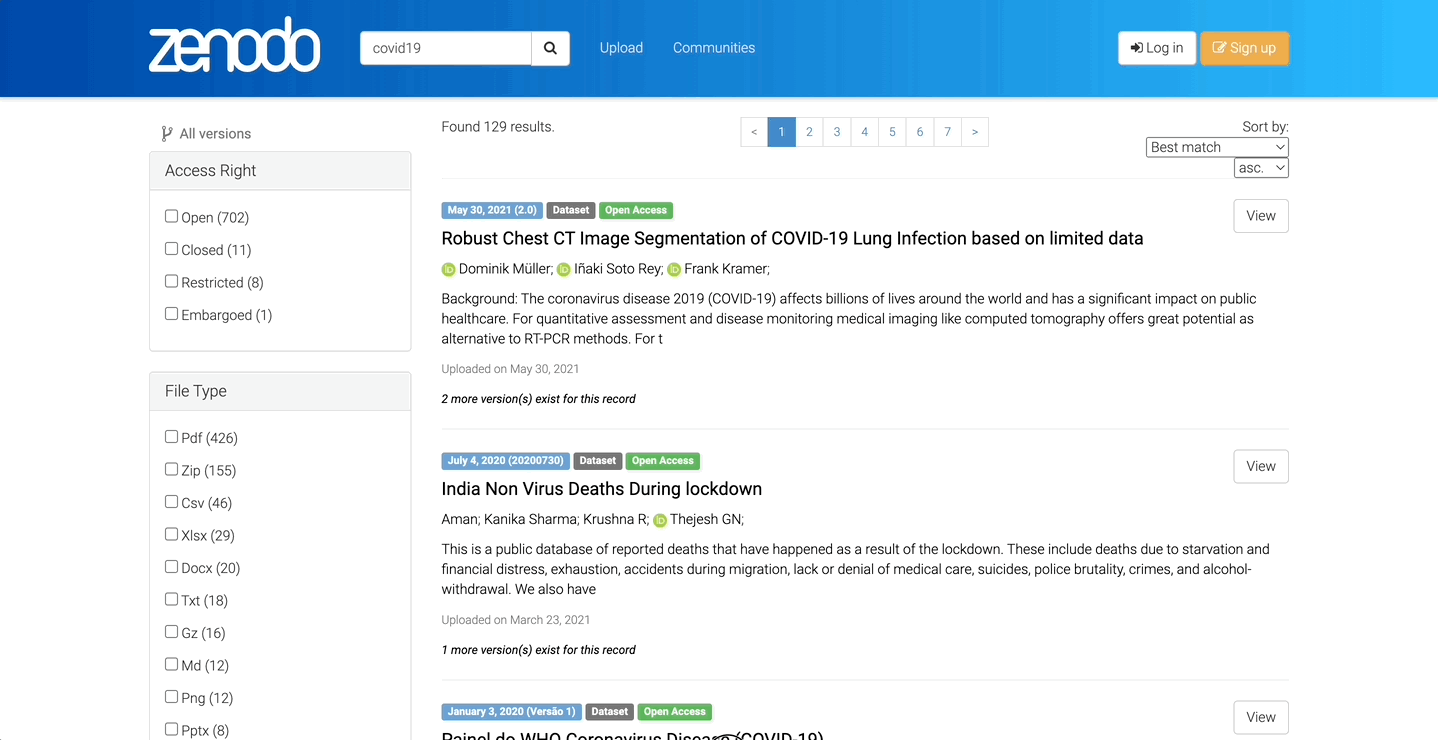 Exemple de recherche de données sur l'entrepôt Zenodo
Exemple de recherche de données sur l'entrepôt ZenodoBien évidemment, tous les entrepôts ne se valent pas et selon le domaine ou la discipline scientifique du chercheur, il peut être nécessaire de faire des recherches assez poussées pour trouver celui qui convient le mieux (nous verrons ces aspects-là par la suite).
Il existe de nombreux entrepôts que l'on peut classer dans différentes catégories, entre autres :
- Entrepôts provenant d'éditeurs scientifiques
- Entrepôts supportés par des institutions
- Entrepôts nationaux
- Entrepôts liés à des disciplines
- Entrepôts multidisciplinaires
- Etc
Comme il n'est pas forcément évident de s'y retrouver, il existe des services complémentaires, appelés annuaires d'entrepôts, qui permettent de rechercher un entrepôt selon plusieurs critères.
Callisto. (2022, 26 octobre). La minute Entrepôt de données. [Vidéo]. Canal-U. https://www.canal-u.tv/134293. (Consultée le 10 mai 2023)
-